予測モデル
[需要予測へ]
一般的な
次の 11 個の予測モデルが利用可能です。
- マニュアル予測 (年間需要に基づく)
- 単純移動平均
- レベルによる指数平滑法
- レベルとトレンドによる指数平滑法
- ナイーブ
- レベルによる適応指数平滑法
- 回帰直線 (最小 2 乗法)
- ベスト フィット (既知の履歴期間における 7 つの予測モデルの中から最適なものを見つける)
- レベルとトレンドによるブラウンの平滑法
- クロストンの間欠型
- 重回帰
- ベイジアン
- ライフ サイクル
- ルール ベース
- TSPT レベル/トレンド/季節
ナイーブ回帰と重回帰を除くすべての予測モデルは、周期的な季節指数と組み合わせることができます。ある期間について計算された基本予測に同じ期間の現在の指数値を掛けると、最終予測が得られます。季節指数は、需要に季節的な変動があるときに使用されます。これらの指標の詳細は、季節指数で説明されています。
導入期
表記
| Y | 予測年間需要 |
| N | 年間の期間数 |
| Dt | 期間 t 内の観測需要 |
| Lt | 期間 t 内の推定レベル |
| Tt | 期間 t 内の推定傾向 |
| 期間 t 内の n 期間先の期間の予測 | |
| t=0 | 過去の需要がある最初の期間 |
| t=h | 過去の需要がある最後の期間 |
| x | 単純移動平均に使用される期間数 |
| n | 予測を行う期間数 |
| a | アルファ: レベルの平滑化定数、 |
| b | ベータ: トレンドの平滑化定数、 |
| r | ロー:長期トレンドを減らすために使用されるパラメーター、 |
1.マニュアル予測
このモデルは、固定された年間需要から期間ごとの平均需要を算出します。予測の開始期間 t と将来の期間に対する有効性 (t + n) は次の式で与えられます。
![]()
2.単純移動平均
移動平均の概念は、時間的に近い観測値は値も近い可能性が高いというものです。したがって、特定の時点に近いポイントの平均を取ると、その期間のトレンド サイクルを合理的に推定できるようになります。平均化により、データ内のランダム性の一部が排除され、滑らかなトレンド サイクル コンポーネントが残ります。予測モデルには明確な傾向がないため、将来の予測は観察の過去 x 期間の平均に等しく設定されます。
この手順を説明するために移動平均という用語が使用されるのは、各平均は最も古い観測値を削除し、次の観測値を含めることによって計算されるためです。たとえば、3 か月の移動平均を使用するとします。1 月の予測は、10 月、11 月、12 月の需要の合計を 3 で割って計算されます。2 月の予測の計算では、10 月が 1 月に置き換わります。
移動平均に基づく一般的な期間予測は、次の式で得られます。
![]()
3.指数平滑法
このモデルは、過去のデータに不均等な加重セットを適用します。加重は通常、最新のデータ ポイントから最も遠いデータ ポイントまで指数関数的に減少します。つまり、モデルは滑らかに減少する加重を使用して過去の観測値の加重平均を取得します。
重量パラメーターは平滑化パラメーターとも呼ばれます。平滑化パラメーターを 0.20 に設定すると、直近の期間には 20% 加重され、次の直近の期間には 16% (= 0.20 � (1 - 0.20)) 加重され、前期は 12.8% 加重されます。これは、この指数計算で最も古い期間に達するまで実行されます。これらの加重の合計は算術的に 1.0 に調整されます。
平滑化パラメーターが最高の推奨値である 1.0 に設定されている場合、モデルは次の期間の予測を最新の期間と等しくなるように計算します。平滑化パラメーターが 0.0 に設定されている場合、次の期間は予測に影響を与えず、元のレベルのままになります。
初期予測値の計算に使用される式
初期予測値は、過去の需要の回帰直線の切片です。以下の指数平滑式の L-1 を参照してください。
現在の予測を計算するために使用される計算式
履歴の最初の期間から始めて、レベルは次の式を使用して更新されます。
![]()
将来の期間 (t + n) における期間 t 内の予測は次の式で得られます。
![]()
4.レベルとトレンドによる指数平滑法
需要が安定した傾向にある場合、移動平均または指数平滑化に基づく予測は、現在の需要に遅れをとります。遅延を解消するのに役立つ追加コンポーネントが必要です。新しい値は以前の値よりも大幅に高くなるか低くなります。トレンド サイクル T は予測の傾きの推定値を表します。現在の需要観測にはランダム性が残っている可能性があるため、トレンド T はパラメーター b で平滑化して修正されます。
レベルとトレンドを更新する原則は同じであり、それぞれ次の式が使用されることに注意してください。
![]() 、
、
![]() 。
。
切片 L-1 と傾き T-1 の値は、次の式で初期化されます。
切片 ![]()
![]()
傾き

将来の期間 (t + n) における期間 t 内の計算された予測は次の式で得られます。
![]()
トレンド効果を意味する削減係数 r が削減されることに注意してください。長期的にはゼロまで減速します。r は 1.0 に近い値に設定する必要があります。r を 1.0 に設定すると、トレンド効果は減少しません。
5.ナイーブ
ランダムウォークとも呼ばれます。この予測では、前期の販売を今期の予測として使用します。
現在の予測を計算するために使用される計算式
![]()
6.アダプティブ指数平滑法
このモデルは指数平滑法と非常によく似ています。ARRSES とも呼ばれます。アダプティブ応答率一次指数平滑法。通常の指数平滑法とこのモデルの違いは、このモデルでは、データのパターンの変化に応じて、アルファの値を制御された方法で変更できることです。このモデルの式は、a (アルファ) の値が a(t) に置き換えられていることを除いて、指数平滑法の式と同じです。
![]()
![]()
![]()
![]()
現在の予測を計算するために使用される計算式
履歴の最初の期間から始めて、レベルは次の式を使用して更新されます。
![]()
将来の期間 (t + n) における期間 t 内の予測は次で得られます。
![]()
開始値は次のとおりです。
L-1 は指数平滑法と同じです。
A-1 = B-1 = 0
h/4 期間の開始アルファが初期値に設定されます。するとアルファ値が修正され始めます。たとえば、品目に 24 期間の過去の需要がある場合、アルファは需要の最初の 24/4 = 6 期間の初期値に設定されます。
7.回帰
この予測モデルは、最小 2 乗法の規則に従って、過去の期間を直線で近似したものです。
回帰直線
![]()
切片 ![]()
![]()
傾き
現在の予測を計算するために使用される計算式
![]()
8.ブラウンズのレベルとトレンド
このモデルは、前述の指数平滑法、修正トレンド モデルと非常によく似ています。唯一の違いは、予測式の a と b が a b と b b に置き換えられていることです。次の式に従って使用される単一のパラメーター a を入力します。

特別なケースとして、a が 0 に設定されている場合は、a b=0 と b b=0 になります
現在の予測を計算するために使用される計算式
レベルとトレンドは次の数式によって更新されます。
![]()
![]()
将来の期間 (t+n) の将来内の予測は次で得られます。
![]()
トレンド効果を意味する削減係数 r は減少し、長期的にはゼロに減速します。r は 1.0 に近い値に設定する必要があります。r を 1.0 に設定すると、トレンド効果は減少しません。
開始値は次のとおりです。
L-1 と傾き T-1 の値は、上記の指数平滑法、修正トレンド モデルの場合と同じです。
9.ベスト フィット
これは、最新の既知の需要に基づいて他のすべてのモデルを競合して実行する予測モデルです。最良の結果を示すモデルがこの部分の予測モデルとして選択され、どの誤差測定を競合のベースにするかを選択できます。最適化するパラメーターとして MAE と MSE を選択できます。測定の最適化を選択する方法の詳細については、サーバー詳細設定の定義を参照してください。予測モデルはさまざまなパラメーターで実行されるため、パラメーターも最適化されます。
最適なパラメーターを検索するために線形ステップが使用されます。ステップ サイズが 0.025 の場合、最適化アルゴリズムは次のように動作します。パラメーター1 = 0 から開始、パラメーター2 は 0 から 1 まで 0.025 ステップで増加します。次に、パラメーター 1 を 0.05 増やし、パラメーター 2 でもう一度実行します。パラメーターが 1 つしかない場合は、最初の実行のみが実行されます。ステップ サイズは、サーバー詳細設定エントリ BestFitNoOfAlphaSteps または BestFitNoOBetaSteps (以下を参照) によって決まります。移動平均モデルは、期間数 (2..n) に対して可能なすべての長さで実行されます。
最適なモデルが選択されると、次の予測モデルが実行されます。
- マニュアル予測 (年間需要に基づく)
- 単純移動平均
- レベルによる指数平滑法
- レベルとトレンドによる指数平滑法
- ナイーブ
- レベルによる適応指数平滑法
- 回帰直線 (最小 2 乗法)
- レベルとトレンドによるブラウンの平滑法
毎の予測モデルが実行され、パラメーターは次のように選択されます。
移動平均
min_average_period_number..n から可能なすべての期間数が試されます。N = この品目の過去の期間数。デフォルトの最小平均期間数は 1 です。
- 最小平均期間数 ForecastModels/BestFitMovingAverageMinPeriods
最小 2 乗法
変更するパラメーターはありません。
EWMA (レベル)
ここでは、アルファが 25 段階 (デフォルト) で 0.01 から 0.3 に変更されます。制限は、次のサーバー詳細設定エントリで変更できます。
- アルファ下限値 ForecastModels\BestFit\EWMA_AlpaStart
- アルファ上限値 ForecastModels\BestFit\EWMA_AlpaStop
- アルファ段階数 ForecastModels\BestFit\NoOfAlphaSteps
EWMA (レベル/トレンド)
ここではアルファが 25 段階で 0.02 から 0.51 に変更されます。ベータは 0.005 から 0.18 まで 25 段階で変更されます (デフォルト)。制限は、次のサーバー詳細設定エントリで変更できます。
- アルファ下限値 ForecastModels\BestFit\EWMATREND_AlpaStart
- アルファ上限値 ForecastModels\BestFit\EWMATREND_AlpaStop
- ベータ下限値 ForecastModels\BestFit\EWMATREND_BetaStart
- ベータ上限値 ForecastModels\BestFit\EWMATREND_BetaStop
- アルファ段階数 ForecastModels\BestFit\NoOfAlphaSteps
- ベータ段階数ForecastModels\BestFit\NoOfAlphaSteps
AEWMA
ここで、アルファの開始値は 0.2 に設定されています。ベータ値は 0.1 から 0.3 の間で 25 段階で変更されます (デフォルト)。制限は、次のサーバー詳細設定で変更できます。
- ベータ下限値 ForecastModels\BestFit\AEWMA_BetaStart
- ベータ上限値 ForecastModels\BestFit\AEWMA_BetaStop
- ベータ段階数ForecastModels\BestFit\NoOfAlphaSteps
サーバー詳細設定には、アルファおよびベータパラメーター検索の段階数を決定する共通変数があることに注意してください。
ロー減衰は変更されません。予測モデルに季節プロファイルが紐付けされている場合、最適化アルゴリズムはすべての計算に季節プロファイルを適用して実行されることに注意してください。
ブラウンズのレベルとトレンド
ここで、アルファ値は 0.01 から 0.3 の間で 25 段階 (デフォルト) で変更されます。制限は、次のサーバー詳細設定で変更できます。
- アルファ下限 ForecastModels\BestFit\Brown_AlpaStart
- アルファ上限 ForecastModels\BestFit\Brown_AlpaStop
- アルファ段階数 ForecastModels\BestFit\NoOfAlphaSteps
10.クロストンの間欠型
この予測モデルは、需要が断続的に発生する品目 (動きの遅い品目) に使用される特別なモデルです。このモデルは、需要の発生と需要の規模を個別に計算しました。
定義
| n | 非ゼロ実需要期間のシリアル番号 |
| n' | 初期化に使用される非ゼロ需要の連結シリアル番号 |
|
|
需要の予想サイズ |
|
|
予想需要間平均間隔 |
|
|
実際の需要間平均間隔 |
インストール
元のアルゴリズムでは、モデルを初期化するためにかなりの量のデータが必要です。多くの場合、断続的な需要の散発的な性質のため、その量のデータは利用できません。ここでは、経験分布を構築する手順に基づく元のアルゴリズムの拡張を紹介します。初期化するには、5 つの過去の需要発生が必要です。まず、手元にある時系列の 5 つの繰り返しをつなぎ合わせて、5 つの過去の需要を 25 回の発生に拡張する必要があります。次に、次の式が適用されます。
![]()
![]()
再帰更新


将来の期間 (t + n) における期間 t 内の予測は次で得られます。
![]()
誤差測定とクロストンに関する注記
通常の指標である MAE、値 MAE、MSE、および ME は、すべての期間の期待値である予測を実際の需要と比較するため、正確です。
MAPE、WMAPE、および RME は、実際の需要がゼロの場合にゼロ除算エラーを発生するため、ゼロ以外の期間でのみ更新できます。したがって、このメトリックは断続的な品目には関係ありません。
PVE とトラッキング シグナルは、断続的な需要がある品目については意味のある解釈をしません。したがって、ユーザーはそれらを無視する必要があります
信頼度間隔は予測付近であり、MAE メトリックに基づいているため、かなり大きくなります。これを外れ値の検出に使用するのは意味がありませんが、すべての期間の平均需要の変動についてのアイデアを提供します。
クロストンと予測調整に関する注記
予測を調整し、クロストンの予測モデルを使用する場合は、詳細ビューの予想需要サイズ フィールドも上下に変更して、予想需要サイズ = 平均調整済予測 * 需要間平均間隔という式が有効になるようにします。ユーザーは詳細ビューの需要間平均間隔フィールドを調整することもできます。これにより、予想需要サイズが変更され、上記の式が有効になります。フィールド Sys。予想需要サイズと Sys。詳細ビューの需要間平均間隔は、上記の計算の結果です。
11.重回帰
重回帰では、予測される変数は 1 つ (例: 販売) ですが、説明変数は 2 つ以上あります (数学的な一般形式については以下を参照)。したがって、販売が予測変数である場合、GNP、広告、価格、競合、時間などのいくつかの係数が販売に影響を及ぼす可能性があります。これらの変数のすべてまたは一部を使用して、この製品の販売予測を計算できます。説明変数は、季節の変化、取引日の変動、休日の変動など、販売に対する時間関連の影響を説明するためにも使用できます。たとえば、季節的な変化を見て、季節的な変化の説明変数を追加するために四半期バージョンを想定してみましょう。次の値を取る 3 つの説明変数を追加します。
| 四半期 | Expvar 1 | Expvar 2 | Expvar 3 |
| 第 1 四半期 | 0 | 0 | 0 |
| 第 2 四半期 | 1 | 0 | 0 |
| 第 3 四半期 | 0 | 1 | 0 |
| 第 4 四半期 | 0 | 0 | 1 |
重回帰モデル
すべての説明変数と品目の過去の需要のデータがある最初の期間から回帰分析を開始します。説明変数にすべての予測期間のデータがない場合、最新の期間が欠落している期間にコピーされます。
![]()
ここで、Yi、X1i、...、Xki は、それぞれ変数 Y、Xi、...、Xi (Y は品目消費量、X� は説明変数) の i 番目の観測値を表し、b0、b1、...、bk は固定されているが未知のパラメーターであり、ei は推定誤差です。
回帰係数の解決
![]()
![]()
最小 2 乗法は、誤差項の 2 乗和の最小値を求めて、最小化する b0、b1、...、bk を見つけるために使用されます。
![]()
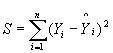
![]()
未知の係数 b0、b1、...、bk のそれぞれに関して S の部分偏差を取り、これらの偏差をゼロに設定し、k 個の未知数を持つ k 個の方程式のセットを解いて、b0、b1、...、bk の推定値を取得します。
![]()
![]()
![]()
.....
方程式 AX=B を解くにはガウスの消去法を使用します。
将来の期間 (t + n) における期間 t 内の予測は次で得られます。
![]()
12.ベイジアン
この予測モデルは、他の 4 つの予測モデルの 1/4 に相当します。使用される 4 つの異なるモデルは次のとおりです。
異なるモデルのパラメーターを見つけるには、ベスト フィット パラメーター検索を実行します。ベスト フィットを参照してください。これは、4 つのモデルそれぞれに対して「最適な」パラメーター セットを見つけることを意味します。このモデルは、4 つのモデルのそれぞれ 1/4 で構成されます。
ベイジアン予測モデルでは、異なるモデルに固定パラメーターを使用することもできることに注意してください。詳細については、サーバー詳細設定の定義を参照してください。
現在の予測を計算するために使用される計算式

サーバー詳細設定エントリ ForecastModels\Bayesian\BayesianInitPeriods を使用すると、ベイジアン モデルが使用される前に、品目に履歴がいくつ必要になるかを定義できます。ベイジアン モデルが選択され、品目に十分な履歴値がない場合は、移動平均 (全期間) が予測モデルとして使用されます。この品目には予測モデルとしてベイジアンがまだ使用されていることに注意してください。品目が制限に達するとすぐに、通常のベイジアンを使用して予測が作成されます。既定値は 4 です。サーバー詳細設定の定義を参照してください。
13.ライフ サイクル
この予測モデルは、有効開始日フェーズを計算するための式と有効終了日フェーズを計算するための式の 2 つの別々の式で構成されています。
フェーズイン:
フェーズ インのパラメーターは、成熟に達したときの予想販売高レベルを意味する飽和レベル、フェーズの最初の期間、開始期間、および終了期間 (フェーズの期間の長さ) の予想販売高である開始レベルです。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
予測は次で得られます。
![]()
フェーズアウト:
フェーズアウトのパラメーターには、成熟に達したときの予想販売レベルとフェーズアウト期間の長さを意味する飽和レベルがあります。
![]()
![]()
![]()
予測は次で得られます。
![]()
飽和の更新
フェーズイン、成熟、フェーズアウトのフェーズでは、実際の販売が予測レベルを上回っているか下回っているかに応じて飽和レベルが変更されます。実際の販売高が下回る場合は飽和レベルが低下し、上回る場合は飽和レベルが上昇します。これは、アルファ平滑化定数を使用した指数平滑法によって行われます。
これは次の式に従って行われます。
![]()
![]()
![]()
![]()
![]()
14.ルール ベース
このモデルにより、利用可能な履歴データ期間の数に基づいて、予測品目/グループ/クエリにマニュアル、移動平均、ベイジアンなどのさまざまな予測モデルを自動的に適用できるようになります。
サーバー詳細設定エントリ ForecastModels\RuleBased\Period_Start_Moving _Average を使用すると、移動平均モデルが使用される前に品目に必要な履歴データ期間数を定義できます。既定値は 3 です。ルール ベース モデルが選択され、品目に十分な履歴値がない場合は、マニュアル モデルが予測モデルとして使用されます。注釈:予測品目の詳細ビューでは、標準予測モデルとして「ルール ベース」が、予測モデルとして「マニュアル」が引き続き表示されます。
サーバー詳細設定エントリ ForecastModels\RuleBased\Period_Start_Bayesian を使用すると、ベイジアン モデルが使用される前に品目に必要な履歴データ期間数を定義できます。既定値は 6 です。ルール ベース モデルが選択され、品目に十分な履歴値がない場合は、移動平均またはマニュアルが予測モデルとして使用されます。注釈:予測品目の詳細ビューでは、標準予測モデルとして「ルール ベース」が引き続き表示され、予測モデルとして「移動平均」または「マニュアル」が表示されます。利用可能な履歴データ期間数が 6 を超える場合は、「ベイジアン」が予測モデルとして表示されます。サーバー詳細設定のエントリ値を選択する方法の詳細については、サーバー詳細設定の定義を参照してください。
15.TSPTレベル/トレンド/季節
このモデルは AI ベースの時系列予測モデルです。TSPT レベル/トレンド/季節は、レベル、トレンド、季節を備えた時系列事前トレーニング済みトランスフォーマーの略で、このモデルにはレベル、トレンド、季節のコンポーネントが組み込まれているため、季節プロファイルと組み合わせることはできません。このモデルは、時系列予測用に Google Research が開発した TimesFM (時系列基盤モデル) に基づいています。これは、1000 億の実世界の時点の大規模な時系列コーパスで事前トレーニングされています。事前トレーニング済みのデコーダーのみの基礎モデルには、予測を作成するために使用される 2 億個のパラメーターがあります。